|
|
|


1 回复 | 直到 5 年前

|
1
0
这可以更快地完成: 虽然fifo可以工作,但它会阻塞。这意味着你不能在队列中放很多东西——这有点违背了队列的目的。 如果磁盘i/o是读取实际作业的问题,我会感到惊讶:gnu parallel每秒可以运行100-1000个作业。作业最多可达128 KB,因此磁盘最多只能传送128 MB/s。如果每秒不运行100个作业,则队列的磁盘I/O永远不会成为问题。
你可以用
|
推荐文章

|
Frank · 使用NamedPipe块读取文件,尽管使用重叠 7 年前 |
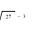
|
Benjamin.E · 从命名管道连续读取 7 年前 |
|
|
Ashish K · 命名管道卡在打开位置 7 年前 |
|
|
Albatross · 使用Java从命名管道连续读取 7 年前 |


|
|
wjimenez5271 · 命名管道的作者什么时候开始工作? 10 年前 |
|
|
bairog · 多个管道服务器实例的异步NamedPipes 10 年前 |