|
|
|


4 回复 | 直到 10 年前

|
1
3
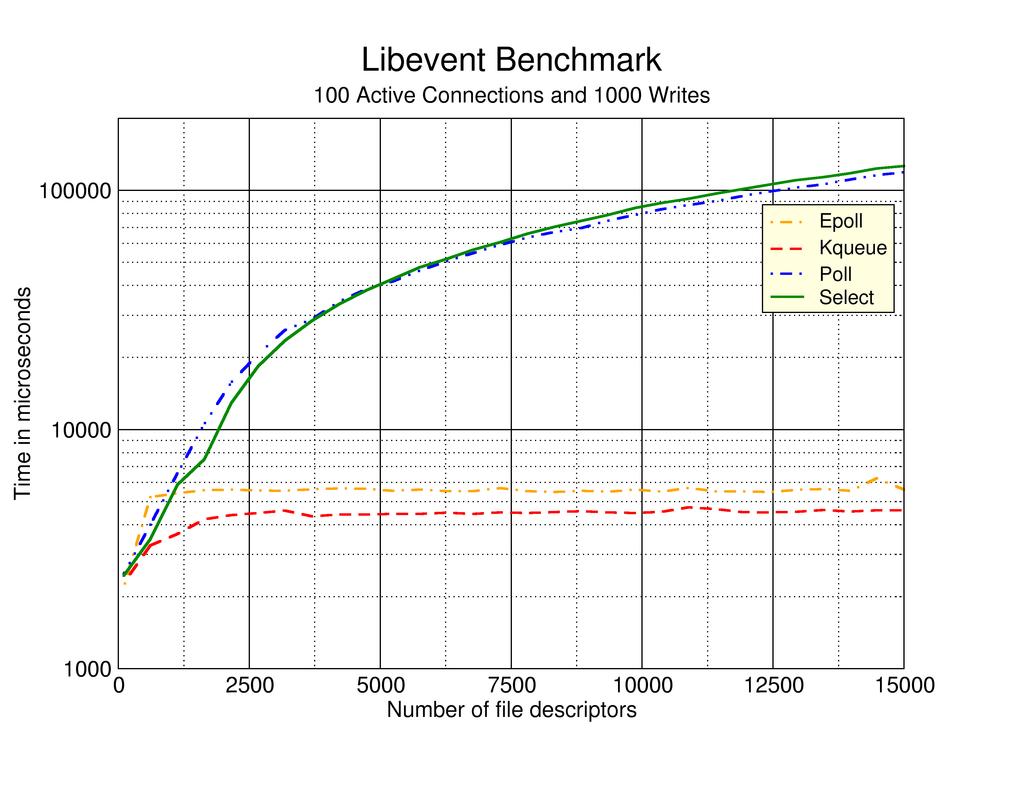
原因是在大约700个客户端上,当我们返回select()时,会有一个客户端可供处理。for()循环扫描以找出哪个客户端会占用大部分CPU。当我们有更多的客户机时,我们会开始在每次调用select()时有越来越多的客户机需要处理,所以我们会变得更高效。 移动到epoll()/kqueue(),类似规格的机器将很容易处理10000个客户机,其中一些机器(功能强大得令人钦佩,但仍被当今标准认为很小的机器)可以容纳30000个客户机而不费吹灰之力。 我在SIGIO上看到的实验似乎表明,它适用于延迟非常重要的应用程序,在这些应用程序中,只有少数活动客户机很少做单独的工作。 我建议在几乎任何情况下都使用epoll()/kqueue()而不是select()/poll()。我没有尝试过在线程之间分割客户机。老实说,我从来没有发现一个服务需要在前端客户端处理上做更多的优化工作来证明线程实验的合理性。 |
|
|
2
2
在过去的两年中,我一直致力于解决这个特定的问题(对于G-wanweb服务器,它附带了许多基准测试和图表来揭示所有这些)。
如果处理很少(低处理延迟),那么使用一个线程将比使用多个线程更快。
我没有认真研究内核中的epoll代码(到目前为止我只关注用户模式),但我的猜测是内核中的epoll实现被锁破坏了。
不言而喻,如果Linux想保持它作为性能最好的内核之一的地位,那么这种糟糕的状态不应该持续下去。 |
|
|
3
2
根据我的经验,你会有最好的表现与#6。
还有,你说的是多少插座?在你开始得到至少几百个套接字之前,你的方法可能并不重要。 |
 .
.
|
|
4
0
我广泛使用epoll(),而且它的性能很好。我经常有数千个插座处于活动状态,并使用多达131072个插座进行测试。epoll()总是可以处理它。 我使用多个线程,每个线程轮询套接字的子集。这使代码复杂化,但充分利用了多核cpu。 |
推荐文章

|
|
CaTx · 使用带有一个大于号和两个大于号的回波的区别 2 年前 |
|
|
Ari157 · x86_64 Linux程序集中的逻辑与实现 2 年前 |
|
|
Ty Q. · 分段故障GLFW3/GLAD 2 年前 |
|
|
ShortArrow · 如何使用git管理链接源文件? 2 年前 |
|
|
Bastien L. · 多Linux Grafana集成 2 年前 |