|
|
|



7 回复 | 直到 6 年前

|
1
30
简单地丢弃点的问题是,可以快速扭曲原始多边形的形状。一个更好的方法是从另一个方向来处理它;从多边形的基本近似值开始,然后向上细化到复杂的形状。 这种方法的一个很好的例子是 Douglas-Puecker algorithm . 从完整多边形中绘制的两个顶点开始。通过选择距离前两个顶点之间绘制的边最远的顶点添加第三个顶点。继续添加点,直到有足够类似于原始多边形的内容为止。 |
|
|
2
61
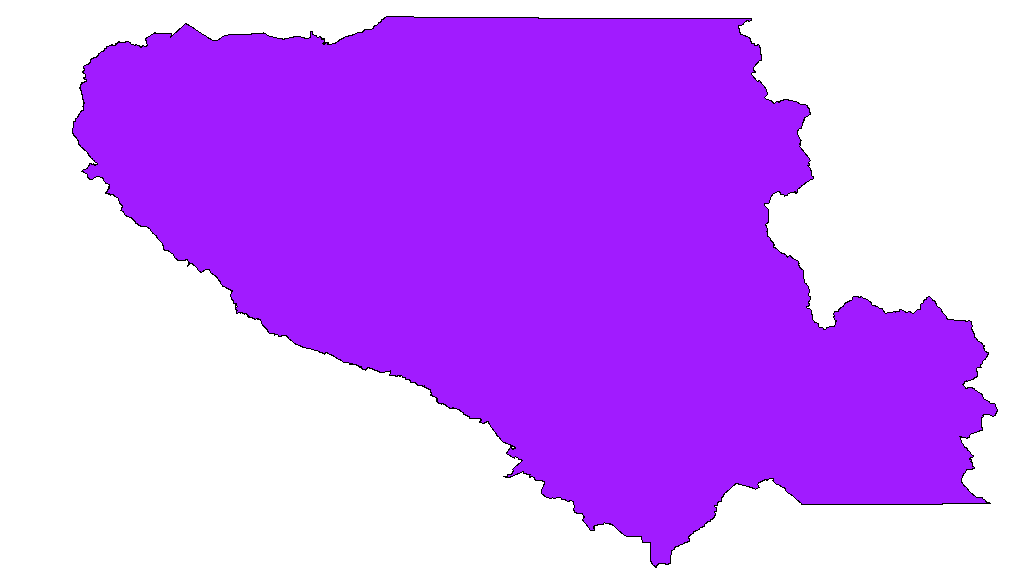
道格拉斯·佩克绝对是正确的方法。有一些简单的方法可以访问Postgis和Qgis中的IT实现,我想在这里为遇到类似问题的人添加这些方法。目标是从这样的事情开始:
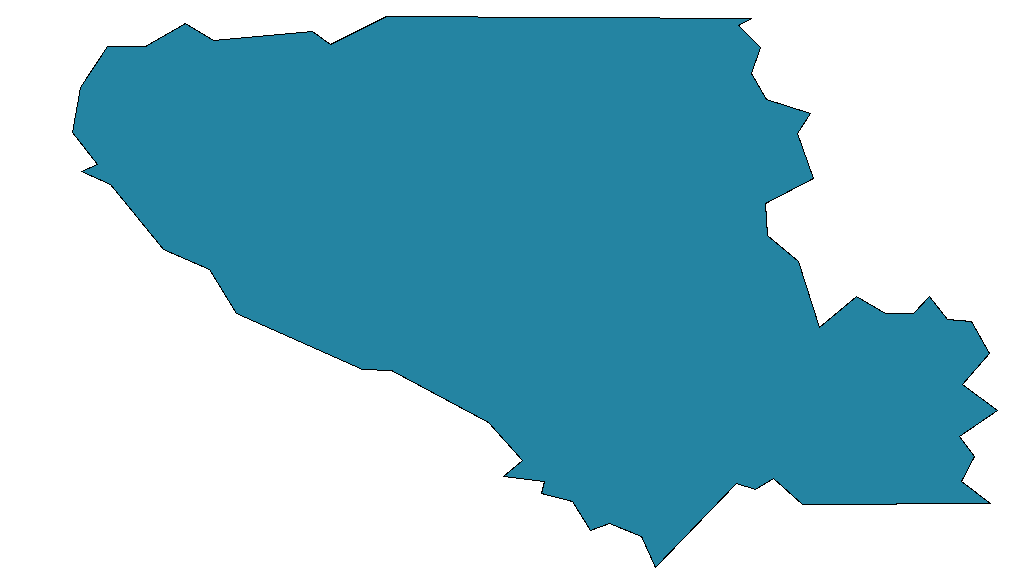
最后是这样的:
在Postgis中,Douglas Peucker实现为
即使是在完整的国家数据集上,这也非常有效,因为一些错误似乎是由糟糕的基础数据造成的。在qgis中,菜单项
这是一个非常基本的工具集,我在很低的水平上问了这个问题,尽管学习基础数学很好,但有一个很好的解释。 here: http://www.mappinghacks.com/code/PolyLineReduction/ 以及证明不太必要的示例代码! |
|
|
3
19
我建议使用ogr2ogr而不是qgis,因为它 does not delete polygons ! |
|
|
4
8
下面是一个简单的迭代平滑算法: 对于任何路径上的每三个连续点,如果中间点没有交点,并且在两个外部点之间的直接路径的某个小阈值角度内,则将其移除。 重复直到满意为止。 |
|
|
5
7
您还可以尝试visvalingam_s算法,它迭代地删除一行中最不易察觉的部分。下面是对该算法的一个很好的解释: |
|
|
6
4
你也可以用 Simplify.js 它结合了 Douglas-Peucker 以及径向距离算法。也有到上列出的其他语言的多个端口的链接。 github project |
|
|
7
0
@unmounted的回答是正确的,但我想再添加一个建议。 在postgis中始终使用函数st-simplifypreservetopology而不是st-simply。两者都使用相同的底层算法(Douglas Peucker),但前者避免了任何可能导致无效几何的简化。例如,st_Simplify可能导致几何体与自身相交。 |
推荐文章

|
|
danial · 如何在多个字符串的每个位置找到最频繁的字符 2 年前 |
|
|
Manny · 如何比较Perl中的字符串? 2 年前 |

|
|
Diret · 获取范围内每个数字的子倍数的算法 2 年前 |
|
|
Saif · 排序时python如何决定何时调用比较器? 2 年前 |